Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!
SERVICES







Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!

Contents
YOLOX (You Only Look Once) is a high-performance object detection model belonging to the YOLO family. YOLOX brings with it an anchor-free design, and decoupled head architecture to the YOLO family. These changes increased the model’s performance in object detection.
Object detection is a fundamental task in computer vision, and YOLOX plays a fair role in improving it.
Before going into YOLOX, it is important to take a look at the YOLO series, as YOLOX builds upon the previous YOLO models.
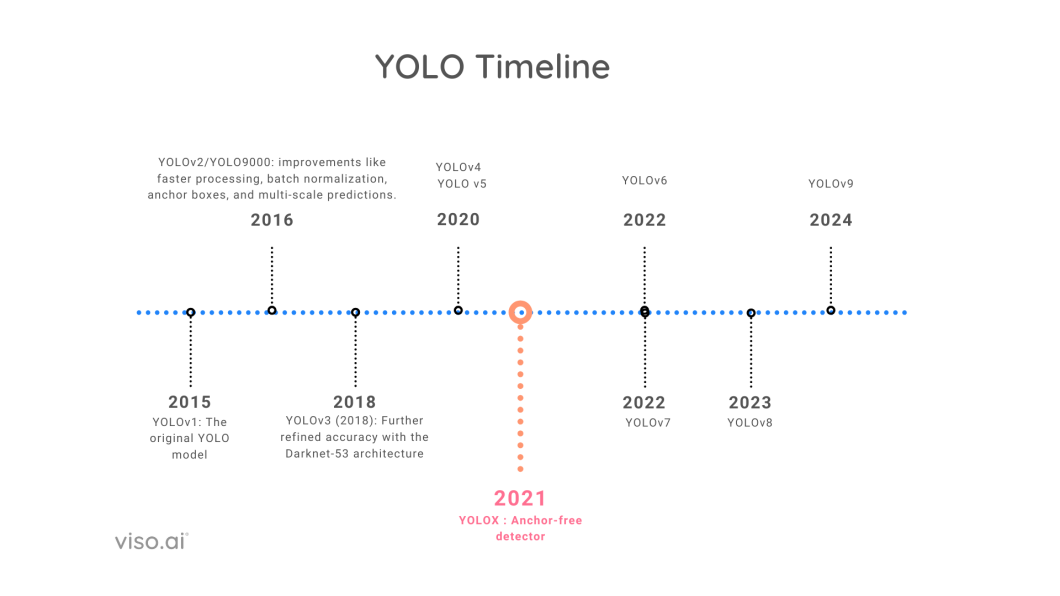
In 2015, researchers released the first YOLO model, which rapidly gained popularity for its object detection capabilities. Since its release, there have been continuous improvements and significant changes with the introduction of newer YOLO versions.
What is YOLO?
YOLO in 2015 became the first significant model capable of object detection with a single pass of the network. The previous approaches relied on Region-based Convolutional Neural Network (RCNN) and sliding window techniques.
Before YOLO, the following methods were used:

Sliding window approach
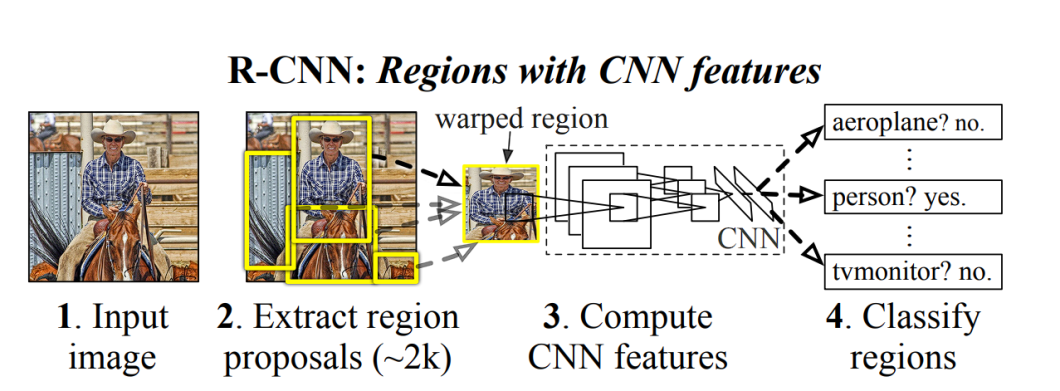
Region Proposal using RCNN
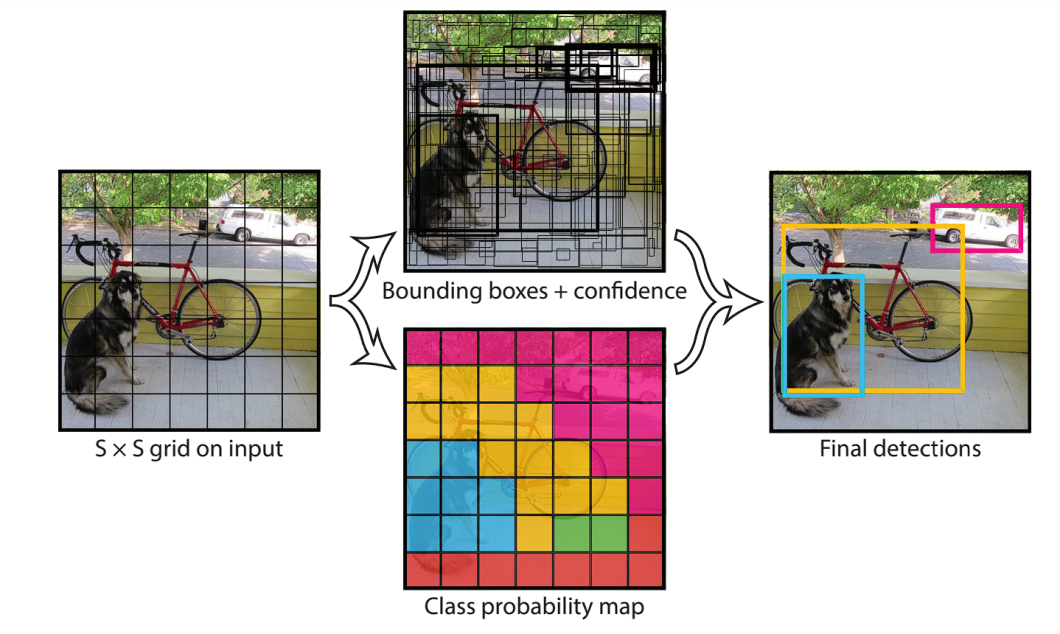
YOLO single staged object detection approach
History of YOLO
The YOLO series strives to balance speed and accuracy, delivering real-time performance without sacrificing detection quality. This is a difficult task, as an increase in speed results in lower accuracy.
For comparison, one of the best object detection models in 2015 (R-CNN Minus R) achieved a 53.5 mAP score with 6 FPS speed on the PASCAL VOC 2007 dataset. In comparison, YOLO achieved 45 FPS, along with an accuracy of 63.4 mAP.
YOLOX performance
YOLO through its releases has been trying to optimize this competing objective, the reason why we have several YOLO models.
YOLOv4 and YOLOv5 introduced new network backbones, improved data augmentation techniques, and optimized training strategies. These developments led to significant gains in accuracy without drastically affecting the models’ real-time performance.
Here is a quick view of all the YOLO models along with the year of release.
Timeline of YOLO Models
What is YOLOX?
YOLOX with its anchor-free design, drastically reduced the model complexity, compared to previous YOLO versions.
How Does YOLOX Work?
The YOLO algorithm works by predicting three different features:
YOLOX architecture is divided into three parts:
What is a Backbone?
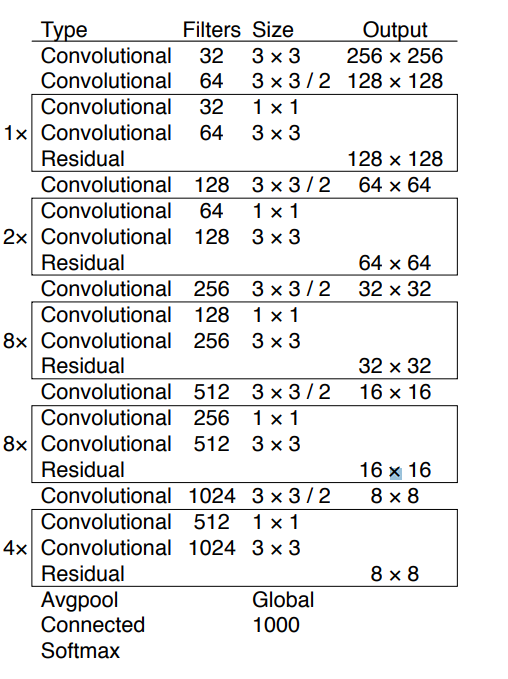
Backbone in YOLOX is a pre-trained CNN that is trained on a massive dataset of images, to recognize low-level features and patterns. You can download a backbone and use it for your projects, without the need to train it again. YOLOX popularly uses the Darknet53 and Modified CSP v5 backbones.
Darknet architecture
What is a Neck?
The concept of a “Neck” wasn’t present in the initial versions of the YOLO series (until YOLOv4). The YOLO architecture traditionally consisted of a backbone for feature extraction and a head for detection (bounding box prediction and class probabilities).
The neck module combines feature maps extracted by the backbone network to improve detection performance, allowing the model to learn from a wider range of scales.
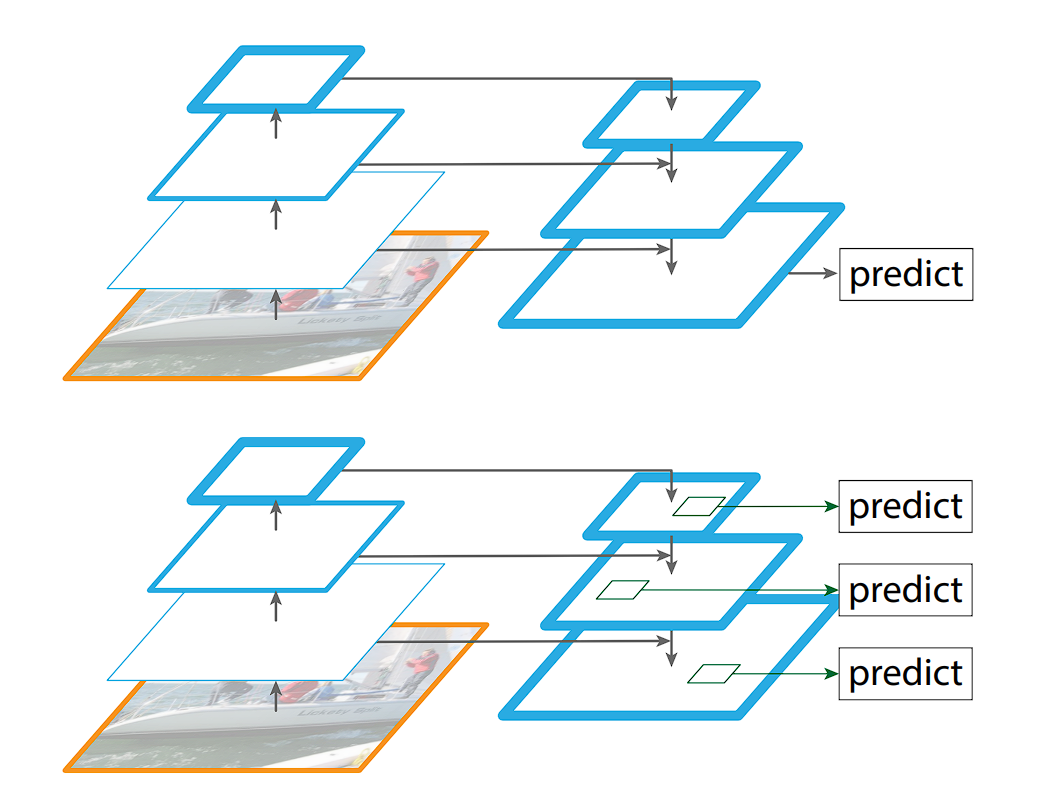
The Feature Pyramid Networks (FPN), introduced in YOLOv3, tackles object detection at various scales with a clever approach. It builds a pyramid of features, where each level captures semantic information at a different size. To achieve this, the FPN leverages a CNN that already extracts features at multiple scales. It then employs a top-down strategy: higher-resolution features from earlier layers are up-sampled and fused with lower-resolution features from deeper layers.
This creates a rich feature representation that caters to objects of different sizes within the image.
Feature Pyramid Network
What is the head?
The head is the final component of an object detector; it is responsible for making predictions based on the features provided by the backbone and neck. It typically consists of one or more task-specific subnetworks that perform classification, localization, instance segmentation, and pose estimation tasks.
In the end, a post-processing step, such as Non-maximum Suppression (NMS), filters out overlapping predictions and retains only the most confident detections.

NMS
YOLOX Architecture
Now that we have had an overview of YOLO models, we will look at the distinguishing features of YOLOX.
YOLOX’s creators chose YOLOv3 as a foundation because YOLOv4 and YOLOv5 pipelines relied too heavily on anchors for object detection.
The following are the features and improvements YOLOX made in comparison to previous models:
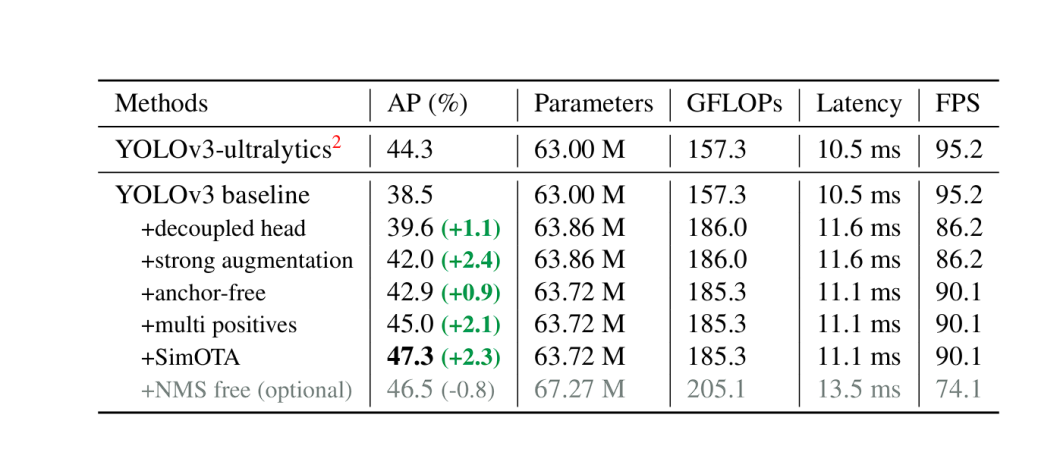
YOLOX performance
Anchor-Free Design
Unlike previous YOLO versions that relied on predefined anchors (reference boxes for bounding box prediction), YOLOX takes an anchor-free approach. This eliminates the need for hand-crafted anchors and allows the model to predict bounding boxes directly.
This approach offers advantages like:
What is an Anchor?
To predict real object boundaries in images, object detection models utilize predefined bounding boxes called anchors. These anchors serve as references and are designed based on the common aspect ratios and sizes of objects found within a specific dataset.
During the training process, the model learns to use these anchors and adjust them accordingly to fit the actual objects. Instead of predicting boxes from scratch, using anchors results in fewer calculations performed.
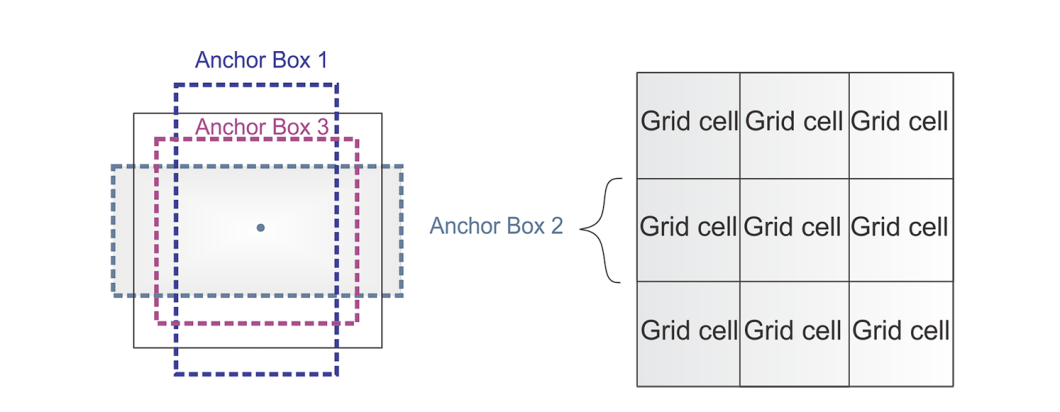
Anchors used in YOLO
In 2016, YOLOv2 introduced anchors, which became widely used until the emergence of YOLOX and its popularization of anchorless design. These predefined boxes served as a helpful starting point for YOLOv2, allowing it to predict bounding boxes with fewer parameters compared to learning everything from scratch. This resulted in a more efficient model. However, anchors also presented some challenges.
The anchor boxes require a lot of hyperparameters and design tweaks. For example,
YOLOX improved the architecture by retiring anchors, but to compensate for the lack of anchors, YOLOX utilized center sampling technique.
Multi Positives
During the training of the object detector, the model considers a bounding box positive based on its Intersection over Union (IoU) with the ground-truth box. This method can include samples not centered on the object, degrading model performance.
Center sampling is a technique aimed at enhancing the selection of positive samples. It focuses on the spatial relationship between the centers of candidate and ground-truth boxes. In this method, positives are selected only if the positive sample’s center falls within a defined central region of the ground-truth box (bounding of the correct image). In the case of YOLOX, it is a 3 x 3 box.
This approach ensures better alignment and centering on objects, leading to more discriminative feature learning, reduced background noise influence, and improved detection accuracy.

Center Sampling
What is a Decoupled Head?
YOLOX utilizes a decoupled head, a significant departure from the single-head design in the previous YOLO models.
In traditional YOLO models, the head predicts object classes and bounding box coordinates using the same set of features. This approach simplified the architecture back in 2015, but it had a drawback. It can lead to suboptimal performance, since classification and localization of the object was performed using the same set of extracted features, and thus leads to conflict. Therefore, YOLOX introduced a decoupled head.
The decoupled head consists of two separate branches:
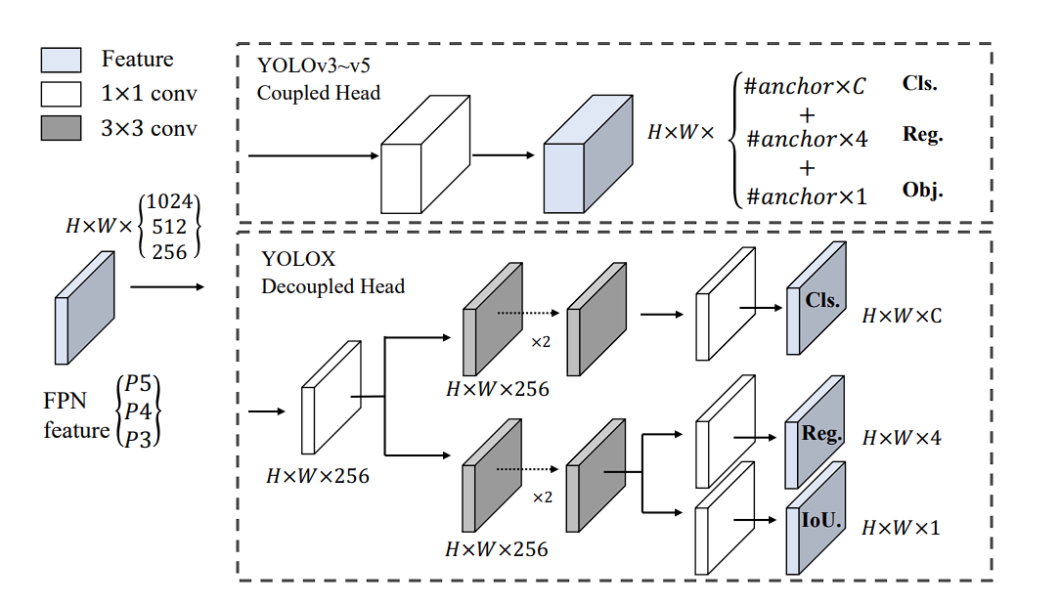
YOLOX decoupled head architecture
This separation allows the model to specialize in each task, leading to more accurate predictions for both classification and bounding box regression. Moreover, doing so leads to faster model convergence.
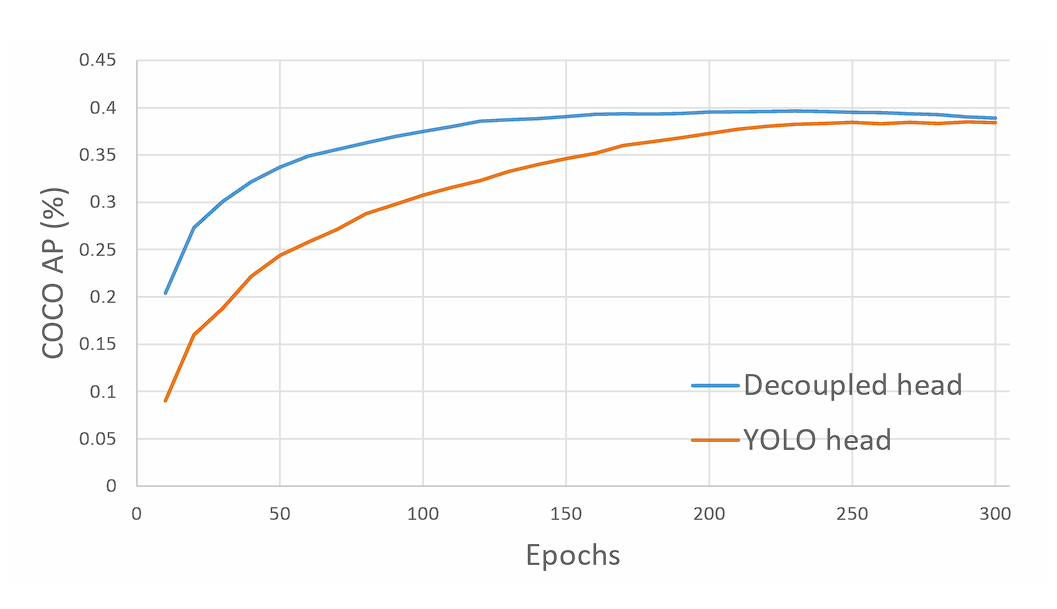
YOLO Convergence using decoupled head
simOTA Label Assignment Strategy
During training, the object detector model generates many predictions for objects in an image, assigning a confidence value to each prediction. SimOTA dynamically identifies which predictions correspond to actual objects (positive labels) and which don’t (negative labels) by finding the best label.
Traditional methods like IoU take a different approach. Here, each predicted bounding box is compared to a ground truth object based on their Intersection over Union (IoU) value. A prediction is considered a good one (positive) if its IoU with a ground truth box exceeds a certain threshold, typically 0.5. Conversely, predictions with IoU below this threshold are deemed poor predictions (negative).
The SimOTA approach not only reduces training time but also improves model stability and performance by ensuring a more accurate and context-aware assignment of labels.
An important thing to note is that simOTA is performed only during training, not during inference.
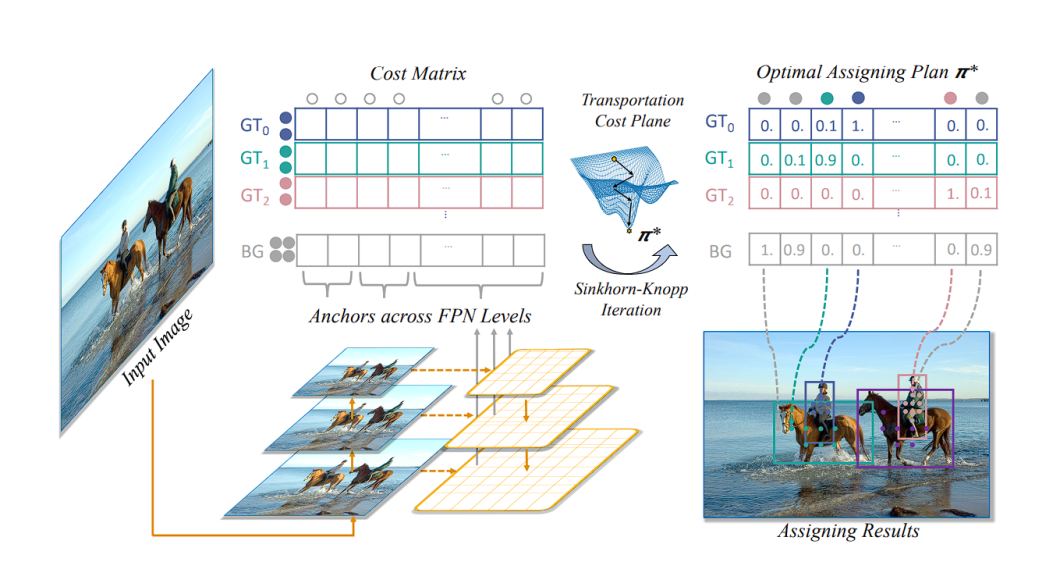
simOTA Label Assignment
Advanced-Data Augmentations
YOLOX leverages two powerful data augmentation techniques:
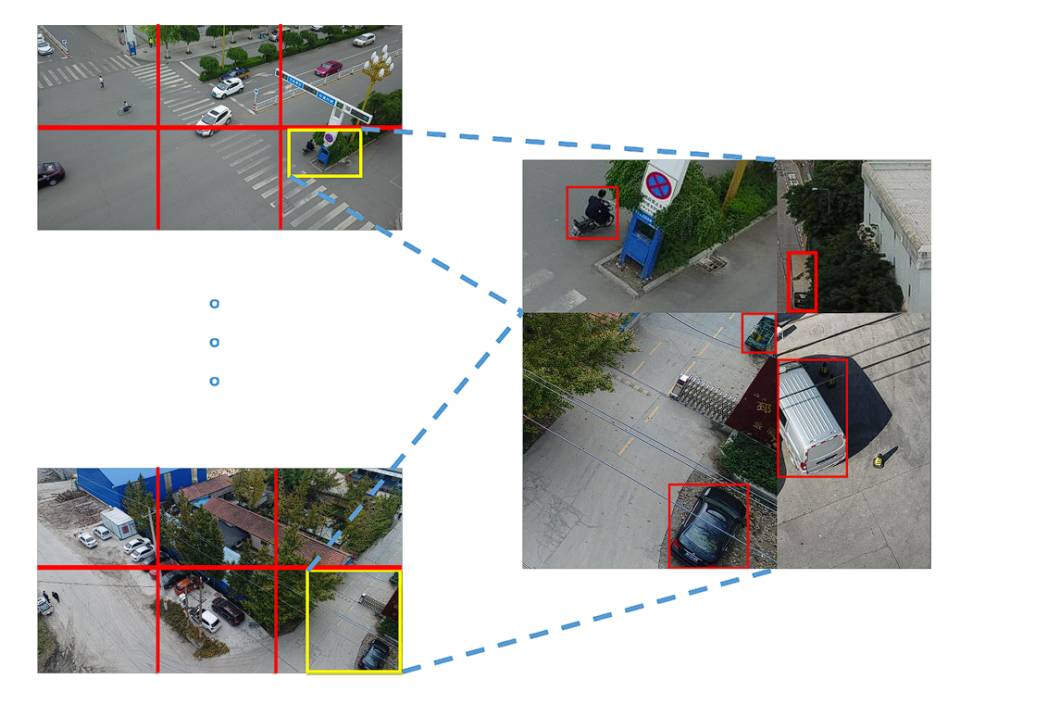
Mosaic Augmentation
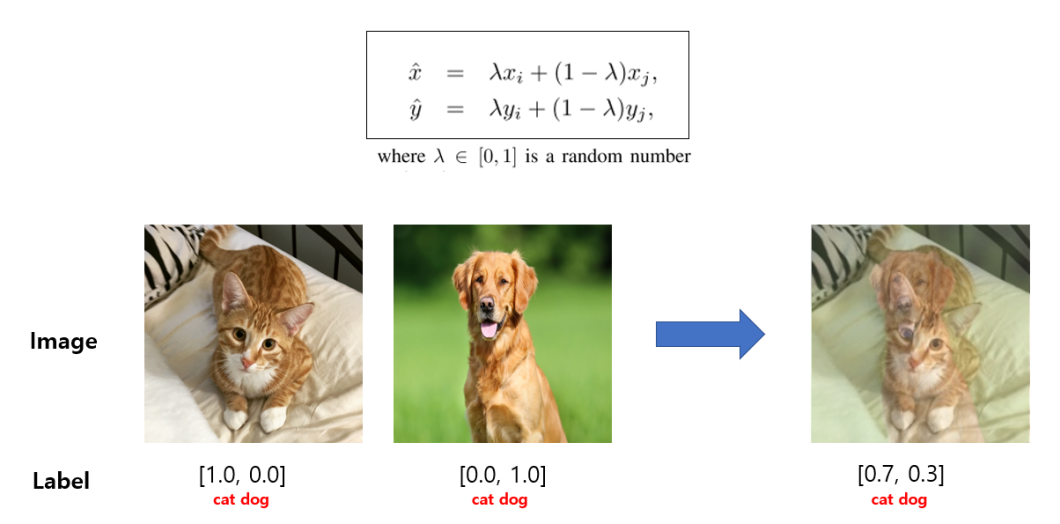
MixUp Augmentation
Performance and Benchmarks
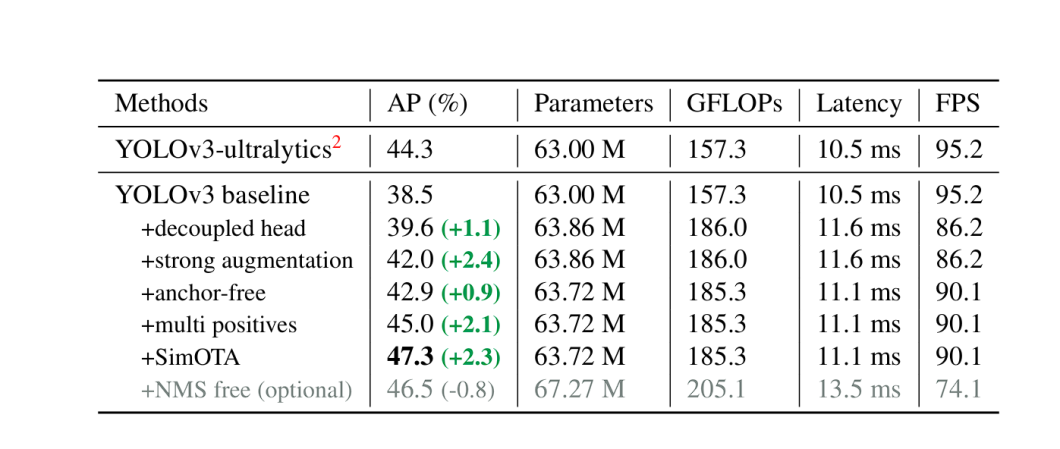
YOLOX with its decoupled head, anchor-free detection design, and advanced label assignment strategy achieves a score of 47.3% AP (Average Precision) on the COCO dataset. It also comes in different versions (e.g., YOLOX-s, YOLOX-m, YOLOX-l) designed for different trade-offs between speed and accuracy, with YOLOX-Nano being the lightest variation of YOLOX.
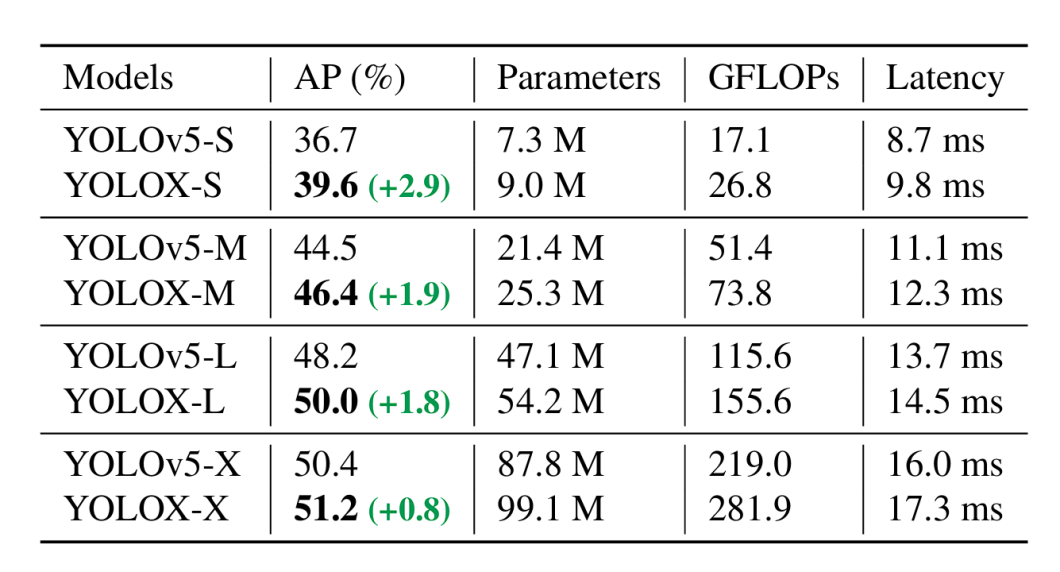
All the YOLO model scores are based on the COCO dataset and tested at 640 x 640 resolution on Tesla V100. Only YOLO-Nano and YOLOX-Tiny were tested at a resolution of 416 x 461.
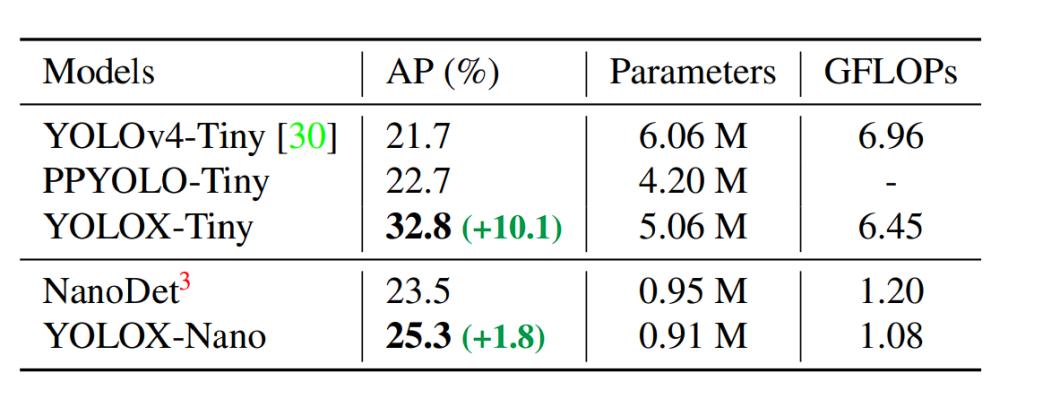
YOLOX lighter models benchmark
What is AP?
In object detection, Average Precision (AP), also known as Mean Average Precision (mAP), serves as a key benchmark. A higher AP score indicates a better performing model. This metric allows us to directly compare the effectiveness of different object detection models.
How does AP work?
AP summarizes the Precision-Recall Curve (PR Curve) for a model into a single number between 0 and 1, calculated on several metrics like intersection over union (IoU), precision, and recall.
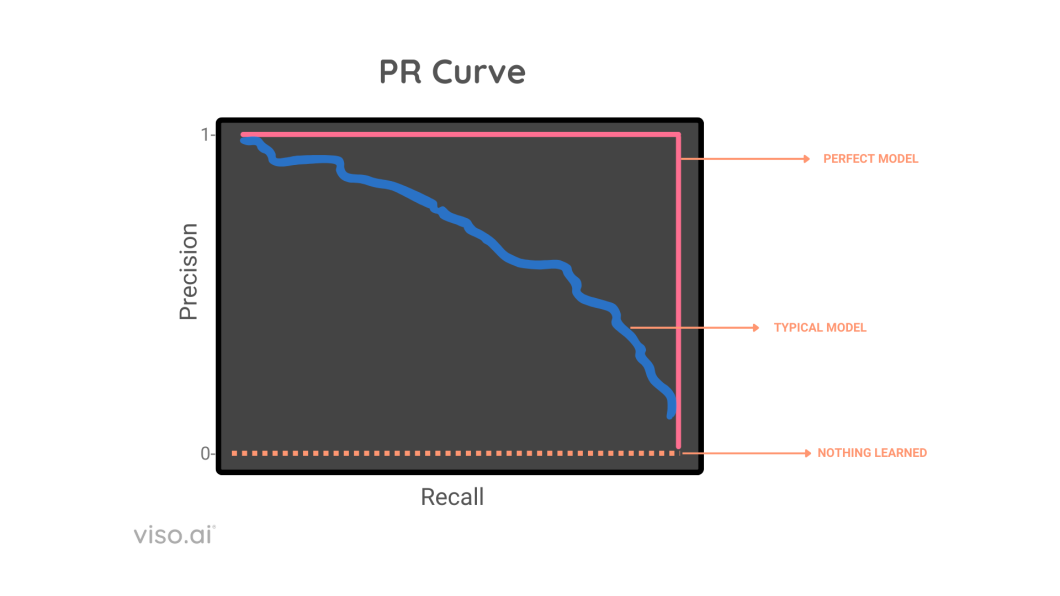
Precision-Recall Curve
There exists a tradeoff between precision and recall, AP handles this by considering the area under the precision recall curve, and then it takes each pair of precision and recall, and averages them out to get mean average precision mAP.


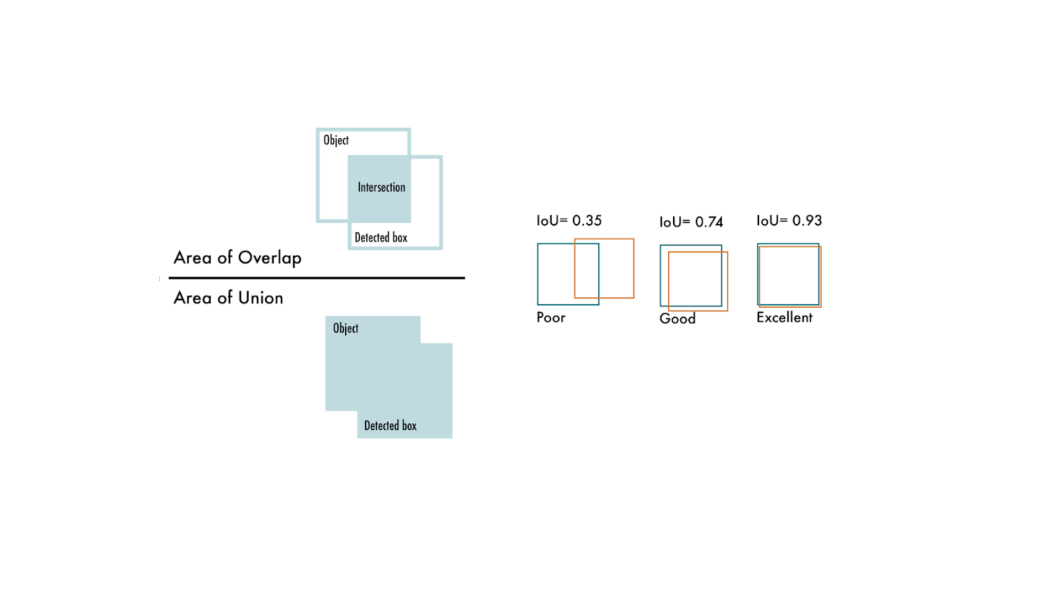
Intersection over Union
How To Choose The Right Model?
The question of whether you should use YOLOX in your project, or application comes down to several key factors.
Application of YOLOX
YOLOX is capable of object detection in real-time makes it a valuable tool for various practical applications including:
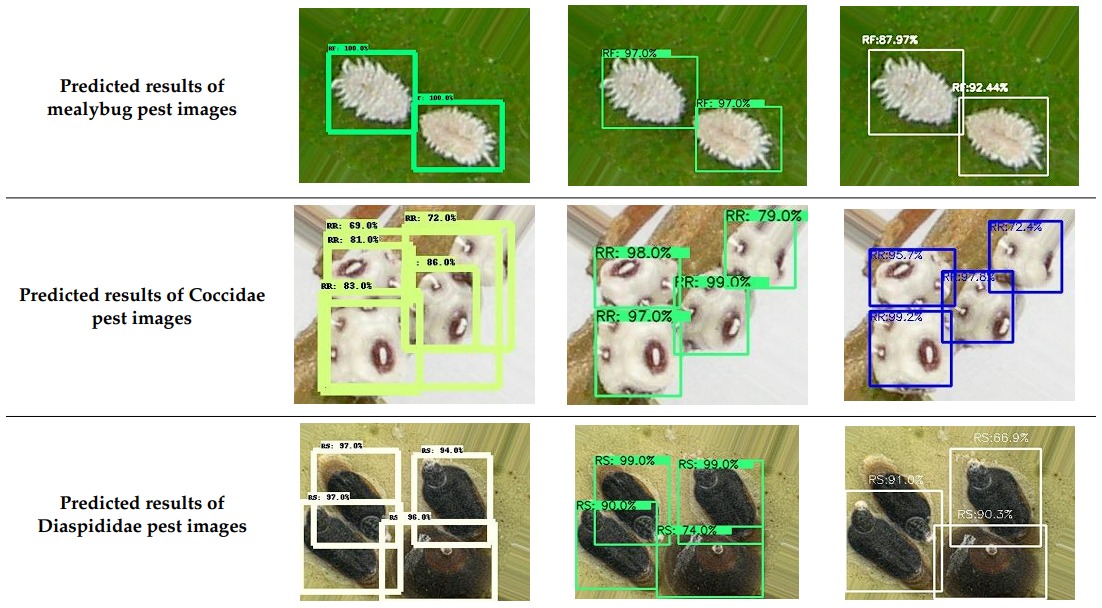
object-detection-agriculture
Cancer detection

Remote Sensing

Traffic detection application

Object detection for inventory management
Challenges and Future of YOLOX
Related Products


Share this: