Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!
SERVICES







Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!

Contents
The latest installation in the YOLO series, YOLOv9, was released on February 21st, 2024. Since its inception in 2015, the YOLO (You Only Look Once) object-detection algorithm has been closely followed by tech enthusiasts, data scientists, ML engineers, and more, gaining a massive following due to its open-source nature and community contributions. With every new release, the YOLO architecture becomes easier to use and much faster, lowering the barriers to use for people around the world.
YOLO was introduced as a research paper by J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based Convolutional Neural Network (R-CNN). It is a single-pass algorithm having only one neural network to predict bounding boxes and class probabilities using a full image as input.
YOLOv9 is the latest version of YOLO, released in February 2024, by Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. It is an improved real-time object detection model that aims to surpass all convolution-based, and transformer-based methods.
YOLOv9 is released in four models, ordered by parameter count: v9-S, v9-M, v9-C, and v9-E. To improve accuracy, it introduces programmable gradient information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN). PGI prevents data loss and ensures accurate gradient updates and GELAN optimizes lightweight models with gradient path planning.
At this time, the only computer vision task supported by YOLOv9 is object detection.

YOLOv9 concept proposed in the paper: YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Before diving into the YOLOv9 specifics, let’s briefly recap on the other YOLO versions available today.
YOLOv1 architecture (displayed above) surpassed R-CNN with a mean average precision (mAP) of 63.4, and an inference speed of 45 FPS on the open-source Pascal VOC 2007 dataset. With YOLOv1, object detection is treated as a regression task to predict bounding boxes and class probabilities from a single pass of an image.
Released in 2016, it could detect 9000+ object categories. YOLOv2 introduced anchor boxes – predefined bounding boxes called priors that the model uses to pin down the ideal position of an object. YOLOv2 achieved 76.8 mAP at 67 FPS on the VOC 2007 dataset.
The authors released YOLOv3 in 2018 which boasted higher accuracy than previous versions, with an mAP of 28.2 at 22 milliseconds. To predict classes, the YOLOv3 model uses Darknet-53 as the backbone with logistic classifiers instead of softmax and Binary Cross-entropy (BCE) loss.

YOLOv3 application for a smart refrigerator in gastronomy and restaurants
2020, Alexey Bochkovskiy et al. released YOLOv4, introducing the concept of a Bag of Freebies (BoF) and a Bag of Specials (BoS). BoF is a set of data augmentation techniques that increase accuracy at no additional inference cost. (BoS significantly enhances accuracy with a slight increase in cost). The model achieved 43.5 mAP at 65 FPS on the COCO dataset.
Without an official research paper, Ultralytics released YOLOv5 also in 2020. The model is easy to train since it is implemented in PyTorch. The model architecture uses a Cross-stage Partial (CSP) Connection block as the backbone for a better gradient flow to reduce computational cost. YOLOv5 uses YAML files instead of CFG files in the model configurations.

Small object detection with YOLOv5 in traffic analysis with computer vision
YOLOv6 is another unofficial version introduced in 2022 by Meituan – a Chinese shopping platform. The company targeted the model for industrial applications with better performance than its predecessor. The changes resulted in YOLOv6n achieving an mAP of 37.5 at 1187 FPS on the COCO dataset and YOLOv6s achieving 45 mAP at 484 FPS.
In July 2022, a group of researchers released the open-source model YOLOv7, the fastest and the most accurate object detector with an mAP of 56.8% at FPS ranging from 5 to 160. YOLOv7 is based on the Extended Efficient Layer Aggregation Network (E-ELAN), which improves training by letting the model learn diverse features with efficient computation.

Applied AI system trained for aircraft detection with YOLOv7
YOLOv8 has no official paper (as with YOLOv5 and v6) but boasts higher accuracy and faster speed for state-of-the-art performance. For instance, the YOLOv8m has a 50.2 mAP score at 1.83 milliseconds on the MS COCO dataset and A100 TensorRT. YOLO v8 also features a Python package and CLI-based implementation, making it easy to use and develop.

Segmentation with YOLOv8 applied in smart cities for pothole detection.
Since YOLOv9’s February 2024 release, another team of researchers has released YOLOv10 (May 2024), for real-time object detection.
To address the information bottleneck (data loss in the feed-forward process), YOLOv9 creators propose a new concept, i.e. the programmable gradient information (PGI). The model generates reliable gradients via an auxiliary reversible branch. Deep features still execute the target task and the auxiliary branch avoids the semantic loss due to multi-path features.
The authors achieved the best training results by applying PGI propagation at different semantic levels. The reversible architecture of PGI is built on the auxiliary branch, so there is no additional cost. Since PGI can freely select a loss function suitable for the target task, it also overcomes the problems encountered by mask modeling.
The proposed PGI mechanism can be applied to deep neural networks of various sizes. In the paper, the authors designed a generalized ELAN (GELAN) that simultaneously takes into account the number of parameters, computational complexity, accuracy, and inference speed. The design allows users to choose appropriate computational blocks arbitrarily for different inference devices.
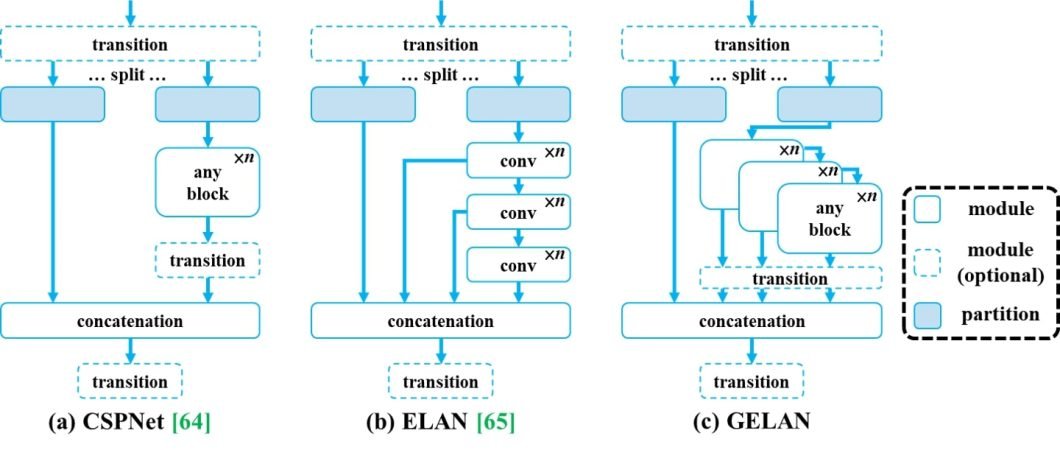
YOLOv9 GELAN Architecture
Using the proposed PGI and GELAN – the authors designed YOLOv9. To conduct experiments they used the MS COCO dataset, and the experimental results verified that the proposed YOLO v9 achieved the top performance in all cases.
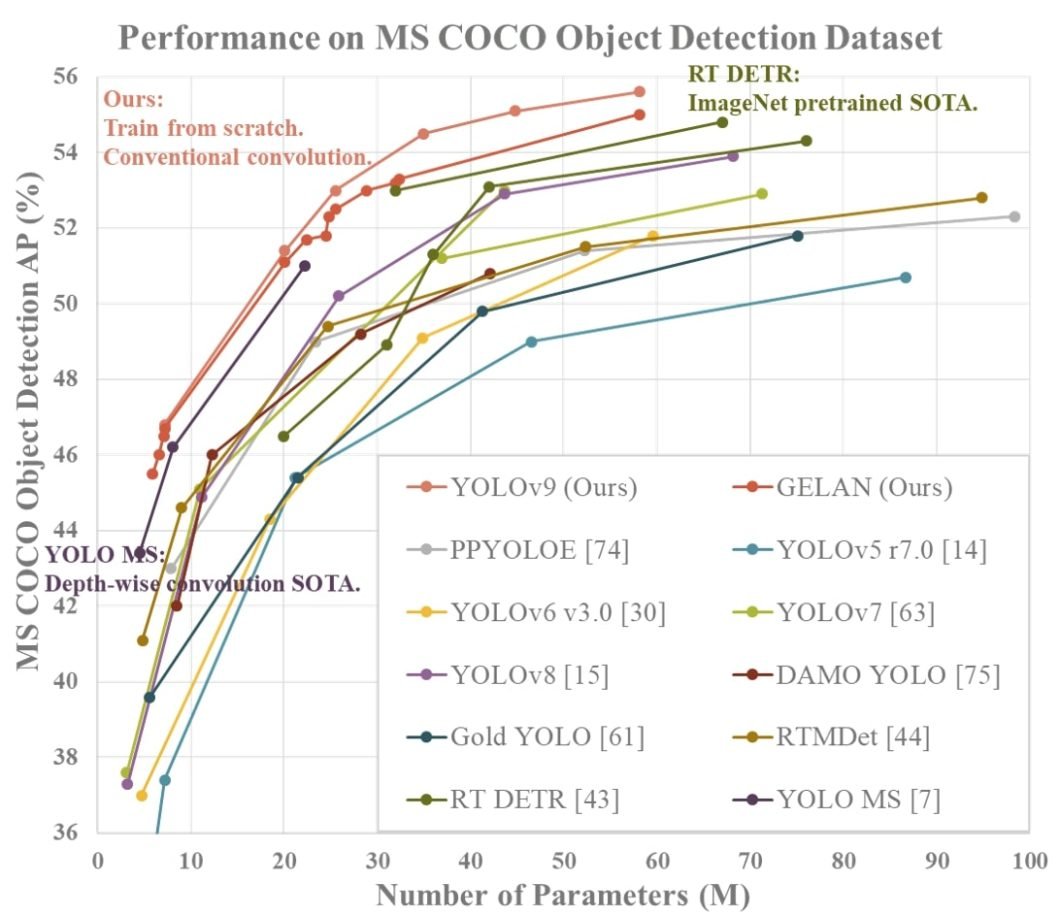
Performance of YOLOv9 against other object detection models on COCO dataset
YOLOv9 arises as a powerful model, offering innovative features that will play an important role in the further development of object detection, and maybe even image segmentation and classification down the road. It provides faster, clearer, and more flexible actions, and other advantages include:
Creating the GELAN, a practical and effective neural network. GELAN has proven its strong and stable performance in object detection tasks at different convolution and depth settings. It could be widely accepted as a model suitable for various inference configurations.
| Model | #Param. | FLOPs | AP50:95val | APSval | APMval | APLval |
| YOLOv7 [63] | 36.9 | 104.7 | 51.2% | 31.8% | 55.5% | 65.0% |
| + AF [63] | 43.6 | 130.5 | 53.0% | 35.8% | 58.7% | 68.9% |
| + GELAN | 41.7 | 127.9 | 53.2% | 36.2% | 58.5% | 69.9% |
| + DHLC [34] | 58.1 | 192.5 | 55.0% | 38.0% | 60.6% | 70.9% |
| + PGI | 58.1 | 192.5 | 55.6% | 40.2% | 61.0% | 71.4% |
The above table demonstrates average precision (AP) of various object detection models.
YOLOv9 is a flexible computer vision model that you can use in different real-world applications. Here we suggest a few popular use cases.

YOLOv9 object detection for detecting customers in check-out queues

Street view detection with YOLOv9
The YOLO models are the standard in the object detection space with their great performance and wide applicability. Here are our first conclusions about YOLOv9:
In the future, we look forward to seeing if the creators will expand YOLOv9 capabilities to a wide range of other computer vision tasks as well.
ProX PC is the end-to-end platform for computer vision. ProX PC offers a host of pre-trained models to choose from, or the possibility to import or train your own custom AI models. To learn how you can solve your industry’s challenges with computer vision, book a demo of VProX PC.
Related Products


Share this: