Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!
SERVICES







Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!

Artificial intelligence (AI) has become an integral part of our lives, with machine learning being a key component in developing AI programs. When it comes to building these programs, programmers often choose between two main approaches: supervised and unsupervised machine learning.
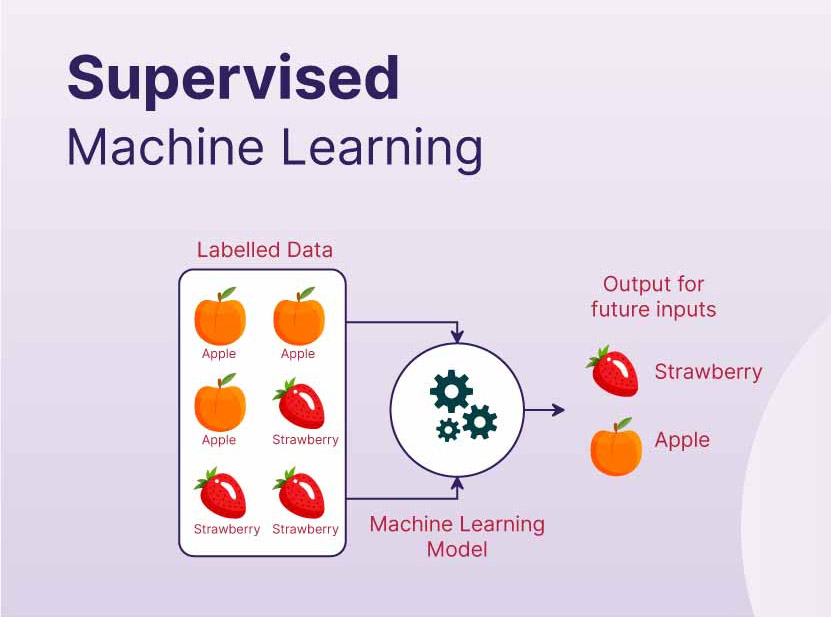
Supervised Learning:
Supervised learning utilizes labeled data to predict outcomes. This means that the model is trained on a dataset where the input data is paired with corresponding output labels. The goal is to learn a mapping from input to output by minimizing the error between the predicted and actual outputs.
Example of Supervised Learning:
Consider the task of predicting whether an email is spam or not. In supervised learning, we would train the model on a dataset of emails where each email is labeled as either spam or not spam. The model learns patterns in the input data (e.g., words, phrases) that are indicative of spam or non-spam emails.
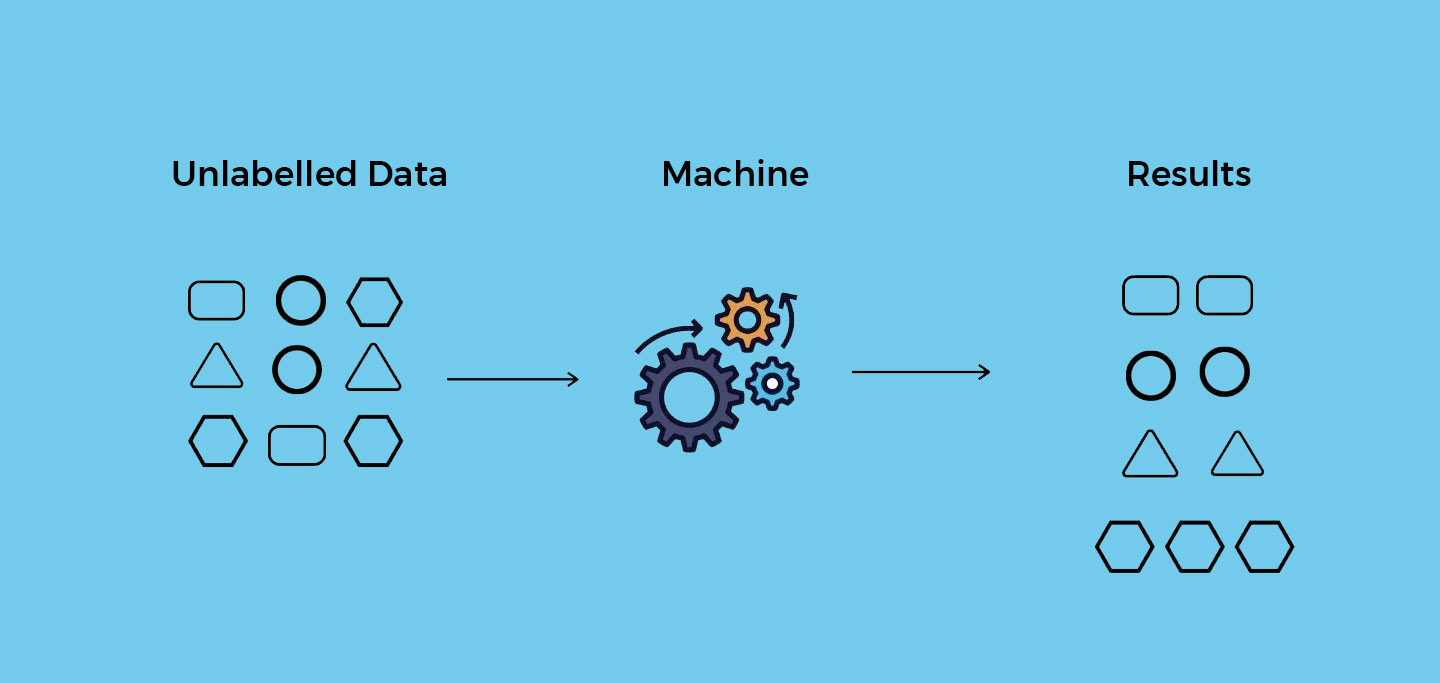
Unsupervised Learning:
Unsupervised learning, on the other hand, does not require labeled data. Instead, the model learns patterns and structures from the input data without explicit supervision. The goal is to discover hidden patterns, structures, or relationships within the data.
Example of Unsupervised Learning:
Clustering is a common task in unsupervised learning where the goal is to group similar data points together. For example, clustering can be used to segment customers based on their purchasing behavior without prior knowledge of customer segments.
Key Differences:
Data Availability: Supervised learning requires labeled data, which can be expensive and time-consuming to acquire. Unsupervised learning can work with unlabeled data, making it more flexible and scalable.
Task Complexity: Supervised learning is well-suited for tasks where the relationship between input and output is known and can be explicitly defined. Unsupervised learning is better suited for tasks where the goal is to explore the structure of the data or discover hidden patterns.
Performance: Supervised learning tends to produce more accurate predictions since it learns from labeled data. However, unsupervised learning can uncover insights and patterns that may not be apparent in labeled data.
Use Cases: Supervised learning is commonly used in applications such as classification, regression, and recommendation systems where labeled data is available. Unsupervised learning is used in clustering, dimensionality reduction, and anomaly detection tasks where the data is unlabeled or the goal is to explore the underlying structure.
Choosing Between Supervised and Unsupervised Learning:

The choice between supervised and unsupervised learning depends on the specific task, data availability, and desired outcomes.
In conclusion, understanding the differences between supervised and unsupervised learning is crucial for choosing the appropriate approach for your machine learning task. Each approach has its strengths and limitations, and selecting the right one depends on the specific requirements and objectives of your project.
For more info visit www.proxpc.com
Workstation Products

AI Development Workstations
View More

Edge Inferencing Workstations
View More

AI Model Training Workstations
View More
Share this: