Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!
SERVICES







Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!

Contents
Object and Image Localization are among the most significant tasks in Computer Vision (CV). In Object Localization (OL), the algorithm identifies and localizes an object in an image. On the other hand, image localization tries to localize all objects within a given image.
There are various applications of object localization. Person identification (surveillance), vehicle ID (traffic control), advanced medical imaging, autonomous vehicles, and sports analytics – all utilize object localization.
However, there are challenges in object and image localization – different object appearance, background clutter, scale/perspective changes, occlusions, etc.
What is Object Localization?
Object localization is an important CV task. It identifies and correctly localizes certain objects within digital images or videos. Object localization’s main goal is to precisely determine the position of objects of interest within an image. Upon that, it represents the object with a bounding box.
The first step in object localization is the object detection. Researchers apply a deep learning model to identify potential objects within an image. The detection step utilizes region proposal networks to identify and mark regions that probably contain objects.
Upon object detection, precise localization refines the detected regions. It draws bounding boxes that contain the identified objects. Also, advanced techniques such as instance segmentation outline the boundaries of objects at the pixel level.
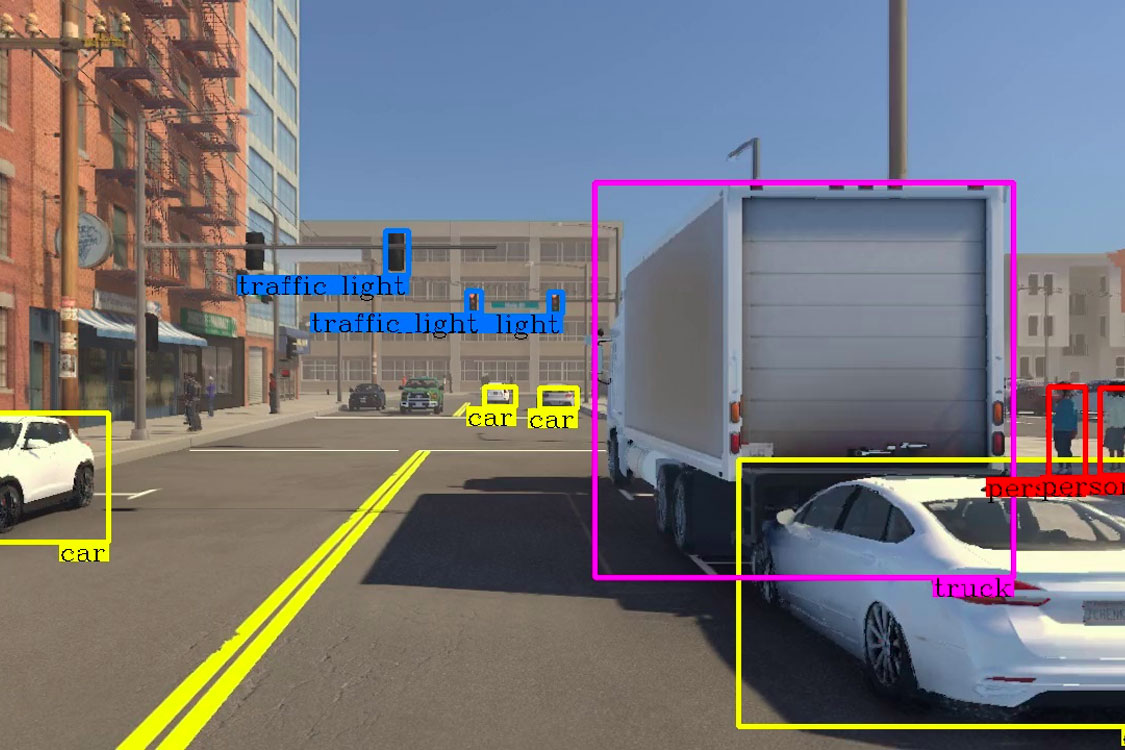
Bounding Boxes for Object Localization
To capture discriminative features from localized objects researchers employ feature extraction techniques. Thus they ensure accurate localization. The features that provide robust and reliable identification include texture, shape, color, or other distinguishing features.
To produce only the correct bounding box predictions, researchers apply post-processing steps, such as bounding box refinement. This will eliminate redundant or overlapping predictions.
OL algorithms enable precise locating and context understanding of objects within complex visual environments. To evaluate the performance of object localization models, they utilize quantitative measurements, e.g. evaluation metrics such as Mean Average Precision (MAP).
Components of Object Localization
The components of object localization include several main phases, each assisting in stable and accurate object identification.
Object Detection
Object localization always starts with the process of object detection. Detection applies a deep learning model to identify potential objects within an image. Engineers utilize different techniques to detect and mark regions with objects, such as CNNs, faster R-CNN, or YOLO.
Bounding Boxes
Upon object detection, the next step is to correctly locate them. The algorithm draws bounding boxes around the identified objects. This approach involves regression models to predict the coordinates of the bounding box relative to the image’s coordinate system.
Instance Segmentation
To define the object boundaries, some localization methods go beyond simple bounding boxes and utilize instance or semantic segmentation. Instance segmentation separates the individual object instances, while semantic segmentation assigns a predicted class to each pixel in the

Instance Segmentation by Clustering Technique
Features Extraction
Feature extraction is an important step in getting discriminative features from localized objects. These features usually include shapes, textures, and other characteristics that enable precise identification of objects within the scene.
Post-processing Steps
To refine the localization results, we need post-processing. Also, post-processing will ensure the elimination of redundant (overlapping) bounding box predictions. Techniques such as bounding box refinement enable filtering out irrelevant predictions. Thus they ensure to keep only the most accurate localization results.
Evaluation Metrics
To evaluate object localization models, we apply metrics such as Mean Average Precision (mAP) and Intersection over Union (IoU). They provide quantitative measures of the accuracy and stability of the localization process.
Object Localization Models and Algorithms
To identify and precisely locate objects within images, object localization algorithms utilize different mathematical techniques. The complete list of algorithms includes:
Shape Localization by Matrix Algebra
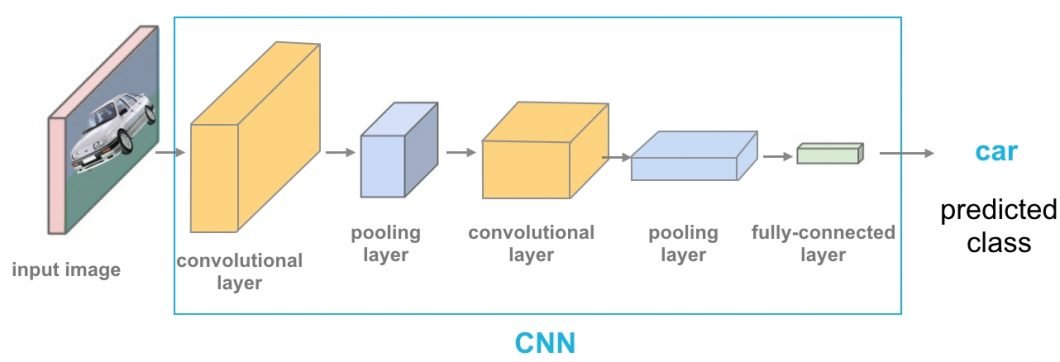
Concept of Convolutional Neural Networks (CNN)
To enable applications in the area of CV, researchers implement object localization by using a deep-learning algorithm, e.g. CNN.
Practical Challenges of Object Localization
Object localization in computer vision is a complex task. Several challenges affect the accuracy and efficiency of the object localization process.
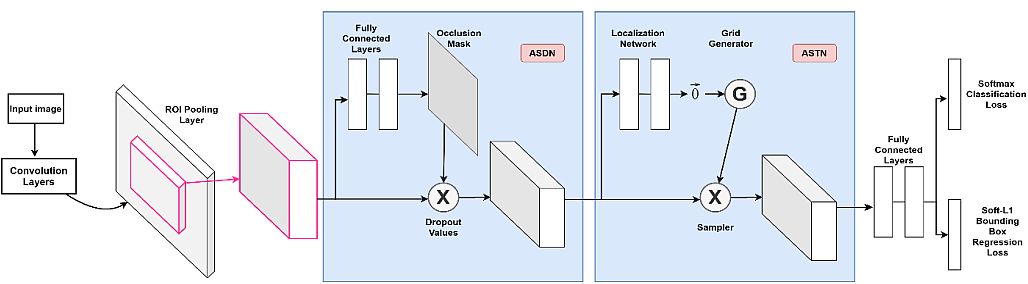
Occlusion Handling by Spatial Transformer Network
Multiple Object Localization
Rambhatla et al. (2023) proposed a new object localization method, Multiple Object localization with Self-supervised Transformers (MOST). It can localize multiple objects in an image without using any labels. It extracts features from a transformer network and trains it with DINO.
They based their approach on two empirical observations:
The algorithm analyzes the similarities between patches only by a fractal analysis tool called box counting. This analysis picks a set of patches that most likely lie on foreground objects. Next, the authors performed clustering on the patch locations. Thus, they grouped patches belonging to a foreground object together.
DINO method
DINO combines self-training and knowledge distillation without labels for self-supervised learning. It constructs two global views and several local views of lower resolution, from an image. DINO consists of a teacher and a student network.
The student processes all the crops while the teacher operates only on the global crops. The teacher network then distills its dark knowledge to the student. Hence, it encourages the student network to learn local to global correspondences.
In contrast to other knowledge distillation methods, the DINO method updates the teacher network dynamically during training. It uses exponential moving averages.
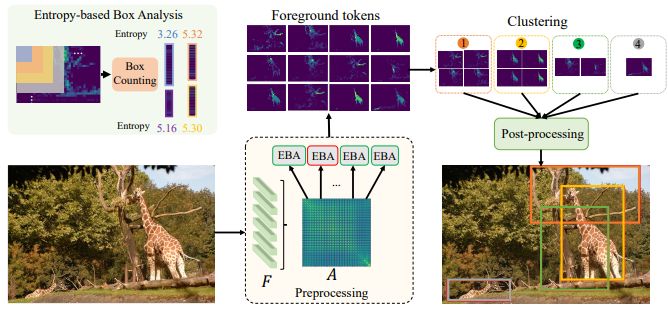
Algorithm for Multiple Objects Localization
Let’s review the example shown in the figure above. Researchers used three examples of the similarity maps of a token (red), picked on the background (column 2) and foreground (columns 3, 4). Tokens within foreground patches had a higher correlation than the ones in the background.
This results in the similarity maps of foreground patches being less random than the ones in the background. The task then becomes to analyze the similarity maps and identify the ones with less spatial randomness.
Box counting is a popular technique in fractal analysis that analyzes spatial patterns at different scales. Subsequently, it extracts the desired properties. Hence, the authors adopted box counting for this case and entropy as the metric.
Object Localization and Image Localization Applications
Image and Video Analysis: It allows efficient analysis of images and videos, including content management, search, and recommendation systems in different domains such as e-commerce and media.
Facial Recognition and Biometrics: It is important in identifying and localizing facial features, thus facilitating applications such as face recognition, biometric authentication, and AI emotion recognition.
Autonomous Vehicles: OL provides vehicles to identify and locate pedestrians, vehicles, and other obstacles in their proximity. Therefore, it facilitates collision avoidance and safe navigation.
Healthcare Imaging: Object localization provides precise detection of specific conditions within medical images. It enables the diagnosis of various diseases, e.g. cancer and brain diseases.
Industrial Quality Control: By detecting and localizing defects, OL enables inspection and assessment of product quality, enhancing quality control processes in manufacturing and production.

Object Localization Applications
Retail Analytics: OL can localize and track products and customers in retail stores enabling customer analytics and behavior understanding. Thus, it improves the marketing strategy and personalizes customer experiences.
Surveillance and Security Systems: This enables detecting and tracking individuals or objects of interest in surveillance footage. Therefore it increases security measures and monitoring capabilities.
Robotics: OL allows robots to perceive and interact with their environment. Therefore, it enables space navigation, object manipulation, and performing complex tasks in industrial and home environments.
Augmented Reality (AR): It facilitates the integration of virtual objects into real-world environments. Also, it enhances the user experience and enables multiple AR applications (gaming, education, and training simulations).
What’s Next?
Image and object localization are quite complex tasks that require advanced deep-learning pre-trained models. But they are essential in many business applications. To learn more about using computer vision AI to solve complex business cases with ProX PC, book a demo with the ProX Pc team.
We provide businesses with a comprehensive platform for building, deploying, and managing CV apps on different devices. Our trained CV models are applicable in multiple industries. We enable computer vision models on edge – where events and activities happen.
Related Products


Share this: