Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!
SERVICES







Discover ProX PC for best custom-built PCs, powerful workstations, and GPU servers in India. Perfect for creators, professionals, and businesses. Shop now!

Contents
The meaning of modality is defined as “a particular mode in which something exists or is experienced or expressed.” In artificial intelligence, we use this term to talk about the type(s) of input and output data an AI system can interpret. In human terms, modality’s meaning refers to the senses of touch, taste, smell, sight, and hearing. However, AI systems can integrate with a variety of sensors and output mechanisms to interact through an additional array of data types.

Pattern recognition and machine learning performed with a variety of cameras and sensors enables systems to identify and interpret meaningful patterns within data to perform specific tasks or solve defined problems.
Understanding Modality
Each type offers unique insights that enhance the AI’s ability to understand and interact with its environments.
Types of Modalities:
Initially, AI systems were focused heavily on singular modalities. Early models, like perceptrons laid the groundwork for visual modality in the 1950s, for example. NLP was another major breakthrough for a variety of modalities in AI systems. While its obvious application is in human-readable text, it also led to computer vision models, such as LeNet, for handwriting recognition. NLPs still underpin the interactions between humans and most generative AI tools.
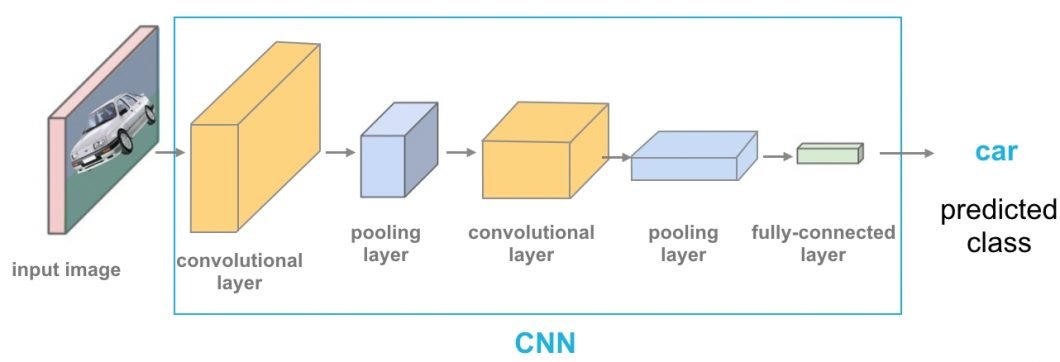
Concept of Convolutional Neural Networks (CNN) modality
The introduction of RNNs and CNNs in the late 20th century was a watershed moment for auditory and visual modalities. Another leap forward occurred with the unveiling of Transformer architectures, like GPT and BERT, in 2017. These particularly enhanced the ability to understand and generate language.
Today, the focus is shifting toward multi-modal AI systems that can interact with the world in multifaceted ways.
Multi-Modal Systems in AI
Multi-modal AI is the natural evolution of systems that can interpret and interact with the world. These systems combine multimodal data, such as text, images, sound, and video, to form more sophisticated models of the environment. In turn, this allows for more nuanced interpretations of, and responses to, the outside world.
While incorporating individual modalities may help AIs excel in particular tasks, a multi-model approach greatly expands the horizon of capabilities.
Breakthrough Models and Technologies
Meta AI is one of the entities at the forefront of multi-modal AI research. It’s in the process of developing models that can understand and generate content across different modalities. One of the team’s breakthroughs is the Omnivore model, which recognizes images, videos, and 3D data using the same parameters.
The team also developed its FLAVA project to provide a foundational model for multimodal tasks. It can perform over 35 tasks, from image and text recognition to joint text-image tasks. For example, in a single prompt, FLAVA can describe an image, explain its meaning, and answer specific questions. It also has impressive zero-shot capabilities to classify and retrieve text and image content.
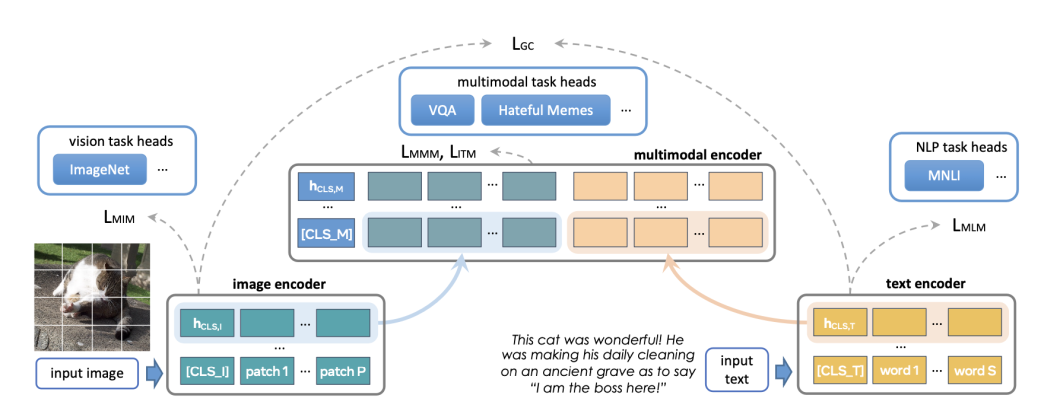
An overview of FLAVA’s architecture. It shows the fusion of image and text inputs for comprehensive multi-task processing.
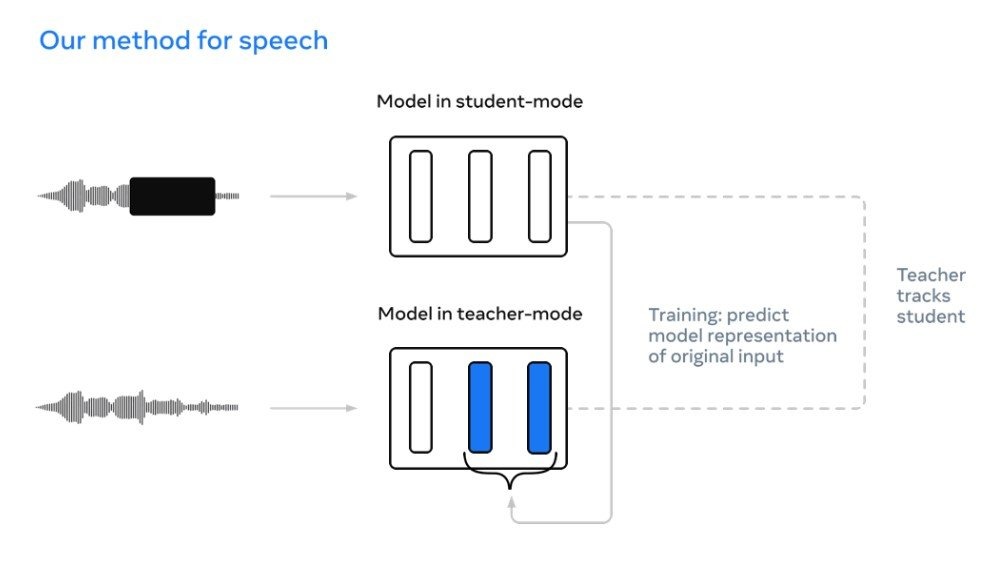
Data2vec, another Meta initiative, proves that “exact same model architecture and self-supervised training procedure can be used to develop state-of-the-art models for recognition of images, speech, and text.” In simple terms, it supports the fact that implementing multiple modalities does not necessitate extreme developmental overhead.
Google has also contributed significantly to the field with models like Pix2Seq. This model takes a unique approach by solving seemingly unimodal tasks using a multi-modal architecture. For example, it treats object detection as a language modeling task by tokenizing visual inputs. MaxViT, a vision transformer, ensures that local and non-local information is combined efficiently.
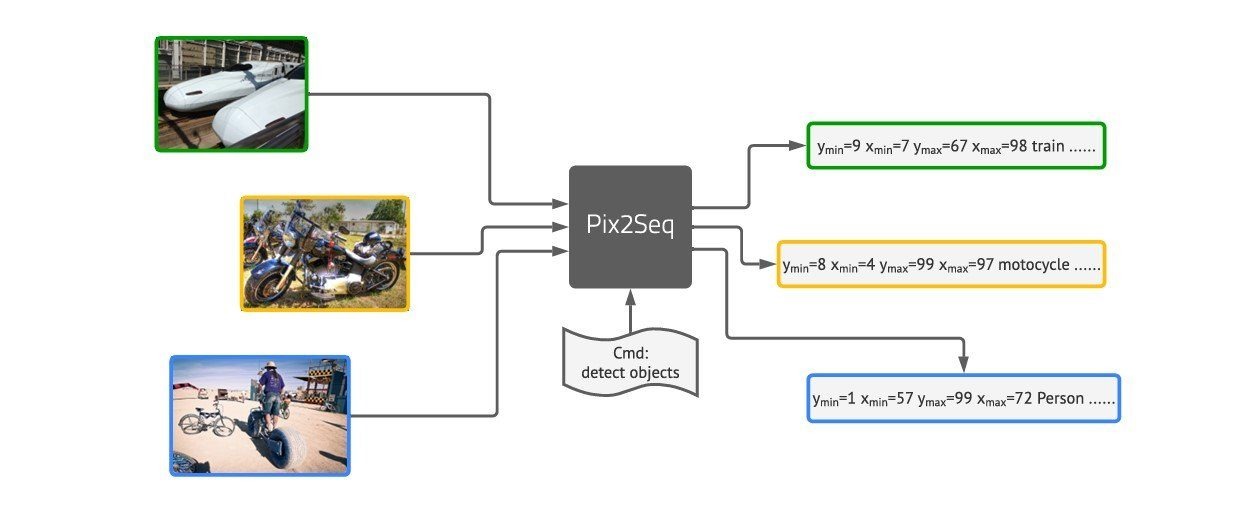
Pix2Seq model workflow: Converting visual inputs into sequenced data tokens for object detection. The model translates images into annotated textual information for various object classes.
On the technology front, NVIDIA has been instrumental in pushing multi-modal AI innovation. The NVIDIA L40S GPU is a universal data center GPU designed to accelerate AI workloads. This includes various modalities, including Large Language Model (LLM) inference, training, graphics, and video applications. It may still prove pivotal in developing the next generation of AI for audio, speech, 2D, video, and 3D.
Powered by NVIDIA L40S GPUs, the ThinkSystem SR675 V3 represents hardware capable of sophisticated multi-modal AI. For example, the creation of digital twins and immersive metaverse simulations.
Real-Life Applications
The applications of multi-modal AI systems are vast, and we’re only at the beginning. For example, autonomous vehicles require a combination of visual, auditory, and textual modalities to respond to human commands and navigate. In healthcare, multi-modal diagnostics incorporate imaging, reports, and patient data to provide more precise diagnoses. Multi-modal AI assistants can understand and respond to different inputs like voice commands and visual cues.
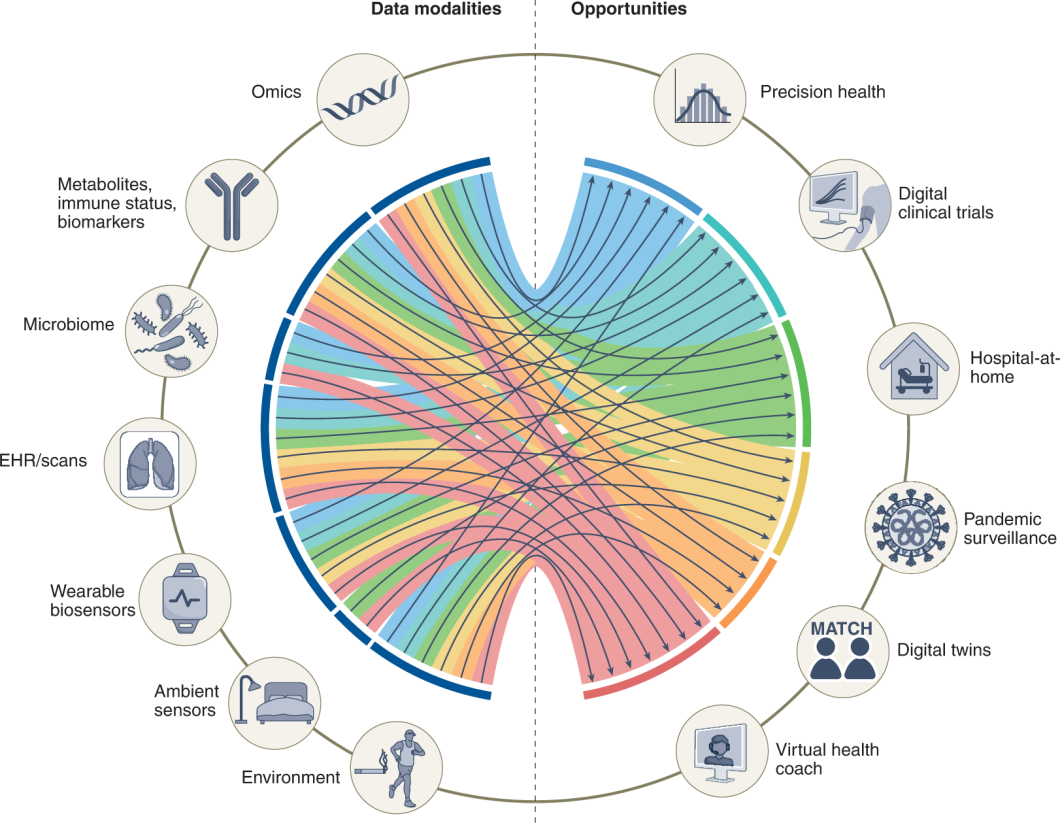
Multimodal AI application in healthcare.
And, at the very forefront, we are seeing advanced new robotics systems using muti-modal capabilities. In a recent demo, Figure 01 demonstrated the ability to combine human language inputs with a visual interpretation. This allowed it to perform typical human tasks in a kitchen, based on verbal instructions. We are seeing similar developments with other competitors, such as Tesla’s Optimus.
The intersection of robot-human interaction facilitated with multimodal AI.
Technological Frameworks and Models Supporting Multi-Modal AI
The success of multi-modal systems necessitates the integration of various complex neural network architectures. Most use cases for multi-modal AIs require an in-depth understanding of both the content and context of the data it’s fed. To complicate matters further, they must be able to efficiently process modalities from multiple sources simultaneously.
This raises the question of how to best integrate disparate data types while balancing the need to enhance relevance and minimize noise. Even training AI systems on multiple modalities at the same time can lead to issues like co-learning. The impact of this can range from simple interference to catastrophic forgetting.
However, thanks to the field’s rapid evolution, advanced frameworks and models that address these shortcomings emerge all the time. Some are designed specifically to help harmoniously synthesize the information from different data types. PyTorch’s TorchMultimodal library is one example such example. It provides researchers and developers with the building blocks and end-to-end examples for state-of-the-art multi-modal models.
Notable models include BERT, which offers a deep understanding of textual content, and CNNs for image recognition. Torch multimodal allows the combination of these powerful unimodal models into a multi-modal system.
This has also led to revolutionary breakthroughs. For example, the development of CLIP has changed the way computer vision systems learn textual and AI representations. OR, Multimodal GPT, which extends OpenAI’s GPT architecture to handle multi-modal generation.
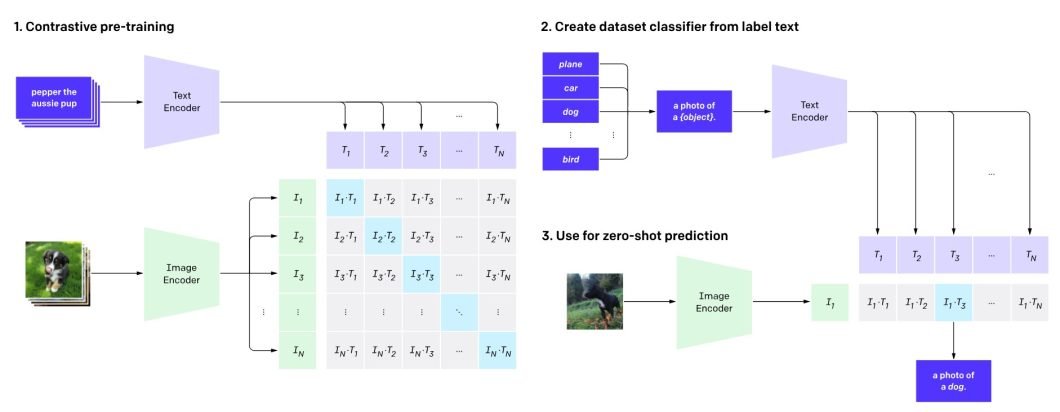
CLIP pre-trains an image encoder and a text encoder to predict which images were paired with which texts in a dataset, turning CLIP into a zero-shot classifier. All of a dataset’s classes are then converted into captions such as “a photo of a dog.” CLIP then predicts the class of the caption it estimates best pairs with a given image.
Challenges to Developing Multi-Modal AI Systems
There are several challenges when it comes to integrating different data types into a single AI model:
Finding solutions to these challenges is a continuous area of development. Some of the model-agnostic approaches, like those developed by Meta, offer the most promising path forward.
Furthermore, deep learning models showcase the ability to automatically learn representations from large multi-modal data sets. This has the potential to further improve accuracy and efficiency, especially where the data is highly diverse. The addition of neural networks also helps solve challenges related to the complexity and dimensionality of multi-modal data.
Impact of Modality on AI and Computer Vision
Advancements in multi-modal predict a future where AI and computer vision seamlessly integrate into our daily lives. As they mature, they will become increasingly important components of advanced AR and VR, robotics, and IoT.

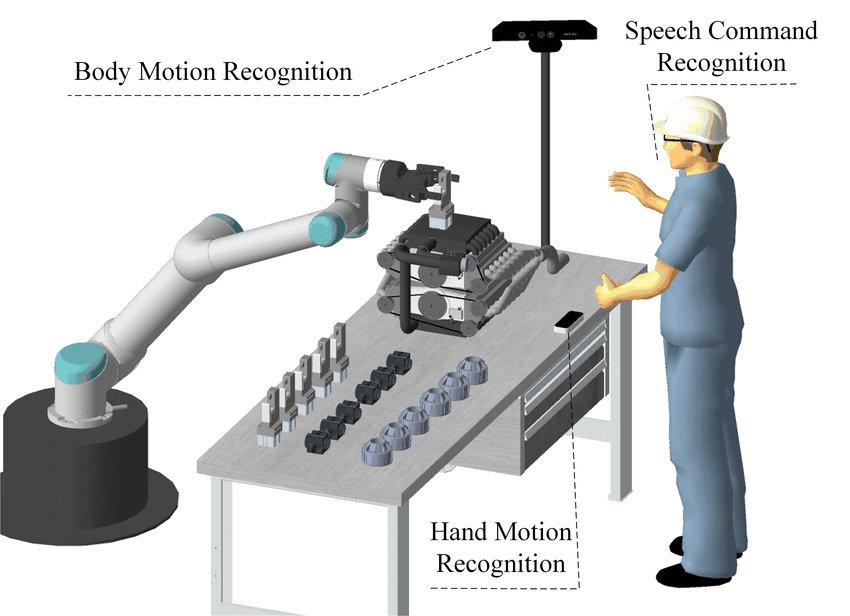
Robotics applied in manufacturing applications to automate physical tasks
In robotics, AR shows promise in offering methods to simplify programming and improve control. In particular, Augmented Reality Visualization Systems improve complex decision-making by combining real-world physicality with AR’s immersive capabilities. Combining vision, eye tracking, haptics, and sound makes interaction more immersive.
For example, ABB Robotics uses it in its AR systems to overlay modeled solutions into real-life environments. Amongst other things, it allows users to create advanced simulations in its RobotStudio software before deploying solutions. PTC Reality Lab’s Kinetic AR project is researching using multi-modal models for robotic motion planning and programming.
In IoT, Multimodal Interaction Systems (MIS) merge real-world contexts with immersive AR content. This opens up new avenues for user interaction. Advancements in networking and computational power allow for real-time, natural, and user-friendly interfaces.
For more info visit www.proxpc.com
Related Products


Share this: