Choose the ideal LSTM variant for your sequential data task: from capturing long-term dependencies to computational efficiency. Future advancements will enhance these tools.

Long Short-Term Memory (LSTM) networks have become pivotal in deep learning for their ability to address one of the biggest challenges in sequential data processing—the vanishing gradient problem. By leveraging unique memory cell mechanisms, LSTMs allow neural networks to retain information over extended sequences, a feat crucial in applications like natural language processing, time series forecasting, and speech recognition.
To fully appreciate the various types of LSTM architectures, let’s briefly explore their evolution and the specific challenges they solve.
In deep learning, recurrent neural networks (RNNs) were among the first architectures designed for sequence-based data processing. The concept was simple yet powerful: these networks used past experiences to improve future predictions. However, RNNs struggled with capturing long-term dependencies due to the vanishing gradient problem. This issue occurs during back-propagation when gradients become too small to pass through several layers, resulting in a network that “forgets” earlier data points in long sequences.
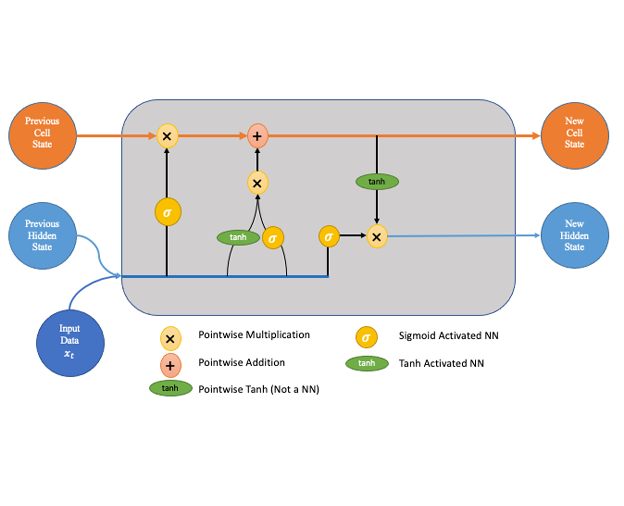
LSTM networks, introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997, tackled the vanishing gradient problem through a persistent cell-state mechanism, or “memory cell.” This feature allows the network to selectively remember or forget information over time, making it far more effective for learning long-term dependencies compared to traditional RNNs. LSTMs continue to be widely used across domains requiring sequential processing, from predictive text generation to financial forecasting.
Now, let’s dive into five primary types of LSTM recurrent neural networks, each with unique features and specialized applications.
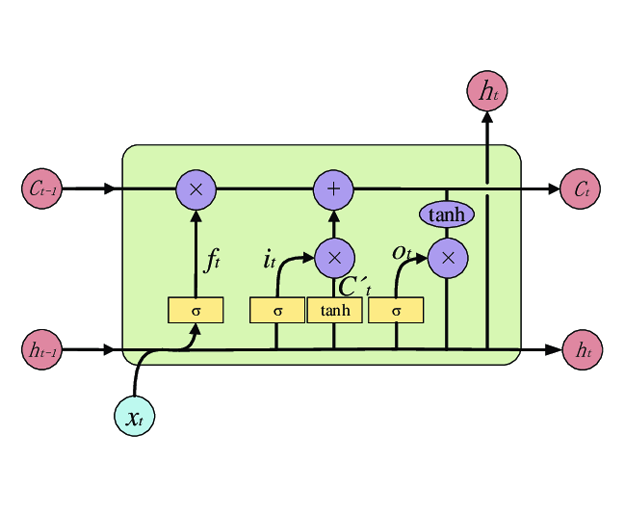
The classic or standard LSTM is the foundation upon which all other LSTM variants are built. Its architecture includes memory cells and three gates: input, forget, and output. These gates control the flow of information, allowing the model to selectively retain or discard data as needed. This flexibility enables classic LSTMs to capture patterns in sequential data and hold relevant information over longer periods, making it highly effective for tasks involving time-based data, like time-series prediction or language modeling.
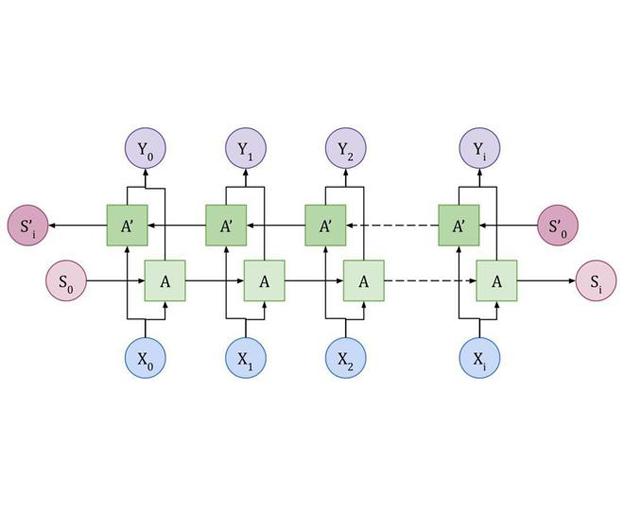
Bidirectional LSTMs enhance the standard LSTM architecture by processing data sequences in both forward and backward directions. By capturing both past and future context, BiLSTMs generate richer representations of input data. This is particularly useful for tasks requiring a holistic view of sequences, such as language translation, where understanding the entire sentence structure is crucial for accurate translation.
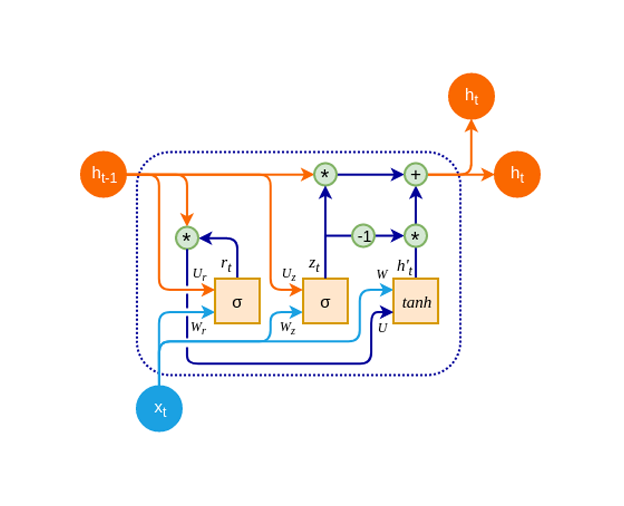
The Gated Recurrent Unit (GRU) is a streamlined version of the LSTM that merges the forget and input gates into a single "update" gate. With a simplified architecture, GRUs are computationally less intensive and can often match or surpass LSTMs in performance on tasks that don’t require complex, long-term memory retention. GRUs are especially popular in applications that need efficient, quick processing, like real-time language translation.
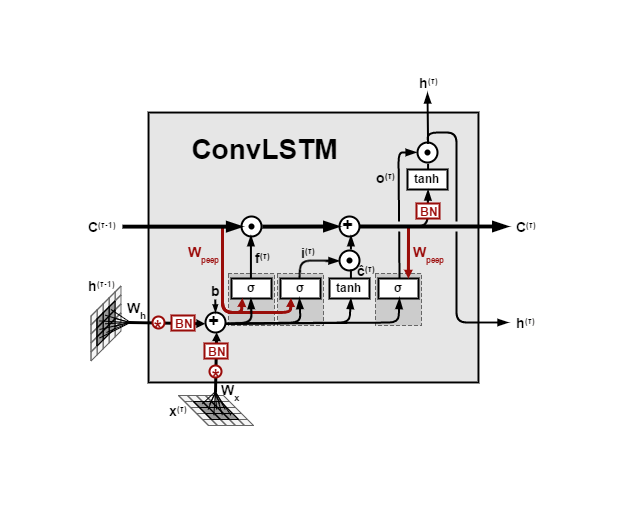
The Convolutional LSTM, or ConvLSTM, combines LSTM and Convolutional Neural Networks (CNNs) to manage spatial and temporal information in data sequences. ConvLSTMs apply convolutional operations to LSTM memory cells, capturing spatial features along with temporal dependencies. This dual capability makes ConvLSTMs ideal for tasks involving both spatial and temporal patterns, such as video frame prediction and dynamic scene analysis.
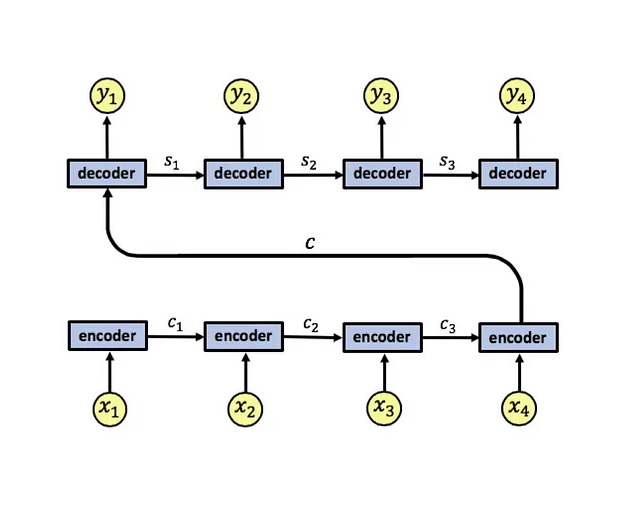
The addition of an attention mechanism to LSTMs represents a significant advancement in sequence-to-sequence tasks. This variant enables the network to focus dynamically on specific parts of an input sequence, enhancing the interpretability of results and capturing fine-grained details. Attention-based LSTMs are widely used in applications that demand precise sequence alignment, such as machine translation, where nuanced understanding of context is essential for accuracy.
Each LSTM variant offers distinct advantages, allowing practitioners to select an architecture tailored to the specific requirements of their task. Whether it’s the long-term memory retention of classic LSTMs, the contextual depth of bidirectional LSTMs, or the computational efficiency of GRUs, each type of LSTM provides a unique approach to managing sequential data. As the field of deep learning continues to evolve, further innovations in LSTM architectures will likely broaden the toolkit available for tackling complex data challenges in sequential processing.
Understanding these different LSTM types is vital for anyone aiming to leverage deep learning in areas such as NLP, video analysis, and predictive modeling. With the right architecture, it’s possible to unlock more accurate, efficient, and interpretable solutions across a variety of domains.
For more info visit www.proxpc.com
Workstation Products

AI Development Workstations
View More

Edge Inferencing Workstations
View More

AI Model Training Workstations
View More
Resources you may find helpful.

Harness the power of GPU servers to revolutionize business operations with unparalleled performance in AI, data analysis, and rendering tasks.

The power of NVIDIA® GeForce RTX 4090: Redefining deep learning benchmarks, exceeding expectations set by the RTX 3090

Best GPUs for AI and deep learning in 2024: NVIDIA's RTX 4090, A6000, A100, and more, benchmarked for performance and efficiency

Keep your computer running smoothly with these 10 essential tips. From regular backups to cleaning dust and updating software, ensure optimal performance and longevity.